Segmentation client data driven : La méthodologie data science
Dans l’article précédent, nous avons décrit l’approche générique à mettre en place pour définir une segmentation client data driven activable. Ici, nous expliquerons les étapes de clustering en nous concentrant sur les méthodologies de traitement des données et algorithmes de data science.
A. Les traitements et algorithmes de segmentation
1. Preprocessing
Le pré-processing est une étape purement technique mais nécessaire à l’utilisation des algorithmes de clustering.
Il est nécessaire de one-hot encoder les variables qualitatives catégorielles, car les algorithmes de clustering reposent sur des calculs de distance et fonctionnent uniquement avec des variables numériques. Afin d’éviter les corrélations, nous effectuons du one-hot encoding.
Fonction utilisée : get_dummies de la librairie Pandas avec l’option drop_first = True.
Pour ne pas biaiser les algorithmes de clustering en sur-pondérant une variable avec une échelle différente, il est également nécessaire de standardiser les variables numériques.
Fonction utilisée : MinMaxScaler de la librairie Scikit-Learn.
La dernière étape du pré-processing consiste à vérifier les corrélations entre variables et traiter. Deux choix sont possibles : supprimer les variables corrélées pour éviter une information redondante ou réaliser une ACP. Concernant la première méthode, nous utilisons un seuil de corrélation à 0,9. Nous conservons la variable qui a le plus de sens métier.
2. ACP
L’analyse en composantes principales a pour but de réduire les dimensions des variables. Elle cherche à trouver une nouvelle base orthonormée dans laquelle on peut représenter les données, telle que la variance des données selon ces nouveaux axes soit maximisée.
Cette analyse est optionnelle mais l’ACP est particulièrement utile lorsque les variables sont fortement corrélées et nombreuses, car dans ce cas elle réduit les variables d’origine en un nombre plus petit de nouvelles variables, tout en gardant la plus grande partie de la variance contenue dans le dataset d’origine. Pour implémenter l’ACP, scikit learn propose la classe décomposition .PCA.
Pour déterminer le nombre de composantes optimales, une des méthodes est de regarder la somme cumulée des inerties valeurs propres et prendre les k axes qui conservent 95% de l’inertie.
Explained variance
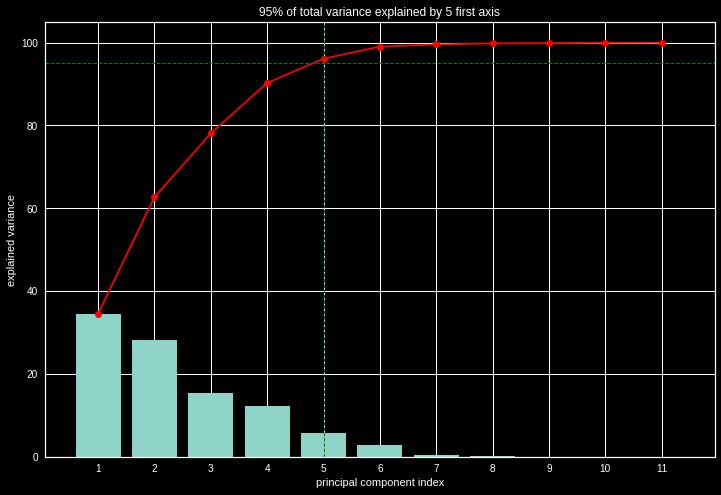
3. Kmeans
Le clustering K-means est l'un des algorithmes de segmentation les plus utilisés. C’est une méthode exploratoire qui utilise une heuristique. Cette méthode est une méthode itérative recherchant les centroïdes des clusters. Après avoir initialisé les centroïdes en prenant des données au hasard dans le jeu de données, le K-Means, regroupe chaque objet autour du centroïde le plus proche et replace chaque centroïde selon la moyenne des descripteurs de son groupe. Ces opérations sont répétées un certain nombre de fois jusqu'à convergence. Le nombre de clusters optimal est à définir par l'utilisateur grâce à la méthode du coude et le coefficient de silhouette.
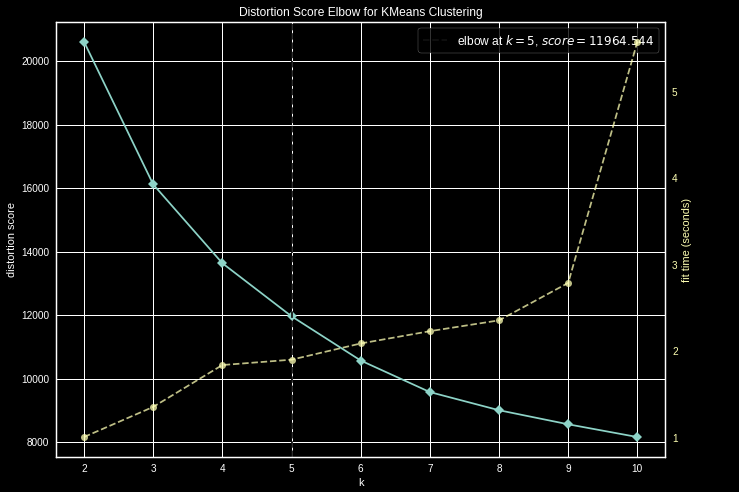
La méthode du coude est une méthode visuelle, elle consiste à calculer la variance des différents volumes de clusters envisagés, puis à placer les variances obtenues sur un graphique. On obtient alors une visualisation en forme de coude, sur laquelle le nombre optimal de clusters est le point représentant la pointe du coude, c'est-à-dire celui correspondant au nombre de clusters à partir duquel la variance ne baisse plus significativement.
Par exemple pour un kmeans de scikit learn, pour obtenir l’inertie, il est possible d’utiliser le package yellobrick puis KElbowVisualizer pour obtenir le graphique suivant. On obtient alors le nombre de clusters recommandé = 5.
Distortion score
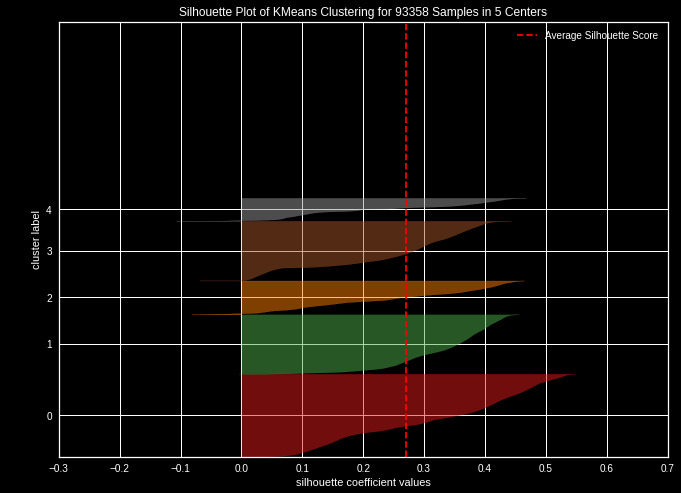
Nous pouvons alternativement utiliser le coefficient de silhouette qui représente la qualité d'une partition d'un ensemble de données en classification automatique. Pour chaque point, son coefficient de silhouette est la différence entre la distance moyenne avec les points du même groupe que lui (cohésion) et la distance moyenne avec les points des autres groupes voisins (séparation). Si cette différence est négative, le point est en moyenne plus proche du groupe voisin que du sien : il est donc mal classé. À l'inverse, si cette différence est positive, le point est en moyenne plus proche de son groupe que du groupe voisin : il est donc bien classé.
Le coefficient de silhouette proprement dit est la moyenne du coefficient de silhouette pour tous les points. Une implémentation est disponible dans scikit learn : metrics / silhouette_score.
Silhouette score
4. ACH
L’algorithme vise à diviser les points en k groupes, appelés clusters, homogènes et compacts. L’approche est différente de celles des Kmeans puisque l’idée de départ est de considérer que chacun des points du dataset est un centroïde. Ensuite chaque centroïde est regroupé selon une distance à définir (par défaut la distance euclidienne) avec son centroïde voisin le plus proche. On calcule alors les nouveaux centroïdes qui seront les centres de gravité des clusters nouvellement créés. On réitère l’opération jusqu’à obtenir un unique cluster ou bien un nombre de clusters préalablement défini.
Attention cependant l’utilisation de L'ACH peut entraîner des problèmes de mémoires, du fait de la complexité, car une distance 2 à 2 est calculée.
Dans un 1er temps, il est nécessaire de faire tourner l’ACH sans déterminer le nombre de clusters. Cela revient à considérer que chaque point est un cluster. L’affichage du dendrogramme permet d’avoir une idée sur le nombre de clusters optimal. Nous pouvons également appliquer la méthode du coude ou le coefficient de silhouette.
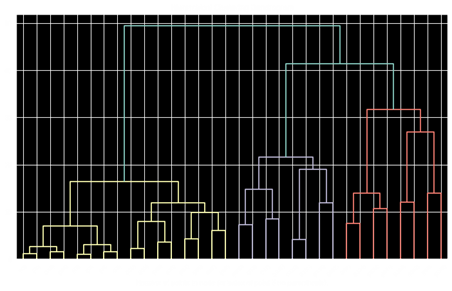
Le dendrogramme permet de visualiser les regroupements successifs jusqu’à obtenir un unique cluster. Il est souvent pertinent de choisir le partitionnement correspondant au plus grand saut entre deux clusters consécutifs.
Le nombre de clusters correspond alors au nombre de lignes verticales traversées par la coupe horizontale du dendrogramme. Dans notre exemple ci-dessous la coupe horizontale correspond aux deux lignes rouges. Il y a 3 lignes verticales traversées par la coupe. On en déduit que le nombre de clusters optimal est 3.
Un dendrogramme est implémenté dans scipy.cluster.hierarchy
Dendrogramme via scipy.cluster.hierarchy
5. Comparaison des 2 méthodes et utilisations
Kmeans
Avantages :
- Clusters sphériques (tous les points du clusters possèdent la même variance)
- Faible coût de calcul
- Convient à un grand jeu de données et fournit une affectation déterministe
Inconvénients :
- Initialisation des centroïdes aléatoires peut donner lieu à des incohérences entre 2 exécutions
- Sensible à des outliers et ne permet pas de découvrir des groupes non convexes
ACH
Avantages :
- Plus précis
- Dendrogramme met en évidence la dispersion des clusters
Inconvénients :
- Ne convient pas aux jeux de données volumineux (distance 2 à 2 pour chaque point)
Ces deux méthodes peuvent être utilisées conjointement pour plus de robustesse :
- ACH avant K-means : pour permettre la réallocation des clients frontières entre 2 clusters du dendrogramme.
- K-means avant ACH : si N est élevé, utilisé un K grand pour la k-means (pour éviter les problèmes de mémoire) .
B. Les traitements et algorithmes permettant l’interprétation de la segmentation
A la suite du clustering, nous disposons pour chacun de nos clients, d’un label faisant référence au cluster auquel il a été assigné. Nous cherchons à qualifier plus précisément les segments, pour ce faire nous allons utiliser deux méthodes:
- L’analyse des variables discriminantes du K-means
- La visualisation des résultats sous la forme d’un arbre de décision
Ensuite nous chercherons à identifier les enjeux de chaque segment et valider les moments clés :
- Interprétation de la fenêtre de temps pour laquelle le K-Means est pertinent
- Nous visualisons également l’évolution des clusters dans le temps et la tendance des clients à passer d’un cluster à un autre à l’aide des chaînes de Markov
- Nous analysons également les parcours clients par segment pour déterminer les moments clés et produits clés des parcours clients à souligner dans la stratégie d’activation
Cette dernière étape est une étape essentielle pour la mise en place d’une stratégie d’activation data driven. L’objectif est d’identifier les éléments objectifs permettant de nourrir la stratégie
1. Analyse des variables discriminantes et interprétation
La première étape est le calcul des moyennes de chaque “feature” par cluster. Nous pouvons visualiser l’impact de ces variables sur chaque cluster avec le “tracé radar”, rendant compte de la valeur des features pour chaque cluster:
Moyenne radar par cluster
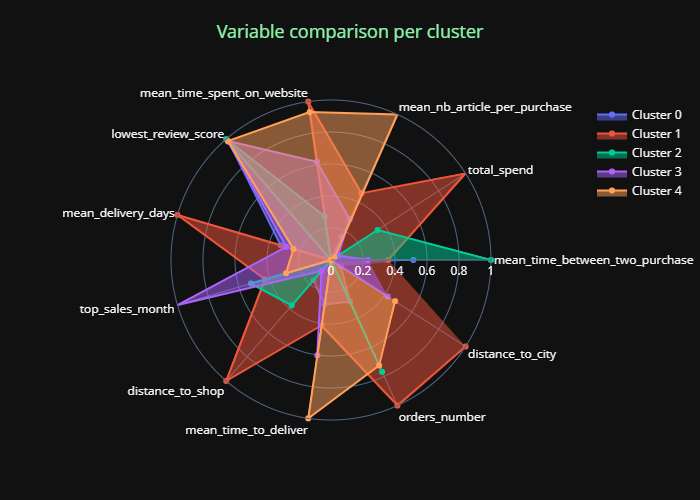
Ce radar facilite l’interprétation de la segmentation, et nous pouvons ainsi en déduire une “fiche ID” des différents clusters, facilitant la compréhension métier.
Cette première méthode d’interprétation a pour avantage de ne se baser que sur les résultats du K-Means. Ainsi, nous sommes sûrs d’en sortir des règles métiers qui correspondent exactement à ce qui est visible via la clusterisation K-Means.
2. Arbres de décision
Enfin, nous pouvons également visualiser à l’aide d’un classifieur type “Arbre de décision”, les variables qui semblent séparer au mieux les différents clusters. Il est possible d’afficher les résutlats d’une classification avec la librairie dtreeviz.
Le but est d’obtenir des règles simples d’affectation pour les clusters pour que les métiers puissent se l’approprier quitte à s’éloigner de la réalité statistique.
3. Stabilité temporelle du K-Means
Afin d’établir la robustesse de l’algorithme de segmentation client, nous devons tester sa stabilité dans le temps, et voir à quel moment les clients changent de cluster. Pour cela nous devons recalculer toutes les features en fonction d’une période donnée (2 mois), et regarder l’évolution dans le temps de notre clustering, à l’aide du score ARI.
L’ARI signifie Ajusted Rand Index, il exprime la probabilité que deux clients différents se trouvent dans le même groupe dans deux segmentations différentes.
L’ARI est utile pour l’interprétation pour une clientèle avec une fréquence d’achat élevé (cela permet de savoir quand un client va changer de segment). La durée dépend du secteur de l’entreprise.
Stabilité de la segmentation Kmeans
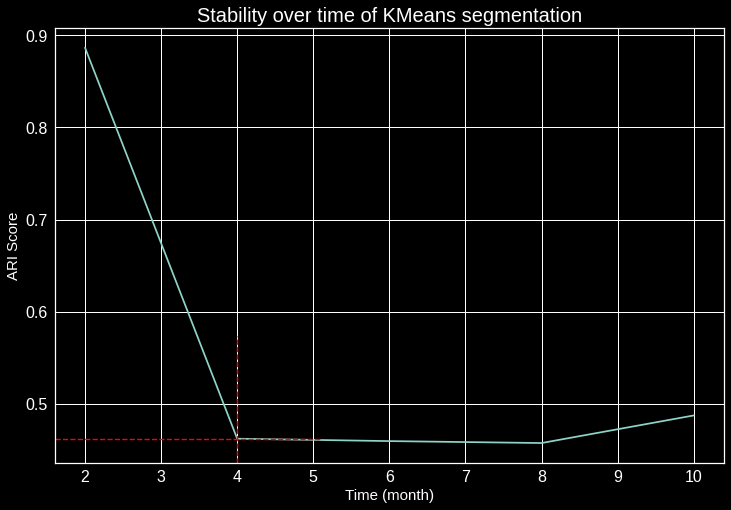
Ce graphique montre que l’inflexion du score ARI débute dès le 2ème mois, on remarque également une forte inflexion après 4 mois sur les clients initiaux. Revoir le programme de segmentation tous les 4 mois est une idée à suivre.
5. Chaine de Markov
Afin d’identifier les enjeux marketing pour chaque segment, nous avons vu qu’il est important de visualiser la stabilité temporelle de la segmentation. Nous allons maintenant analyser les flux vertueux. Soit par simple croisement des segments sur 2 périodes successives soit en utilisant les chaînes de markov pour pouvoir calculer et tracer la probabilité qu'un client a de passer d'un cluster A à un cluster B. Cette méthodologie nous permet d’identifier les chemins vertueux sur le long terme, mais ne peut visuellement être représentée qu’en 2 dimensions. Il faudra donc adopter les deux types d’approches.
Exemple : avec 5 clusters en voyant l’évolution des clusters tous les 2 mois.
Transition des clusters
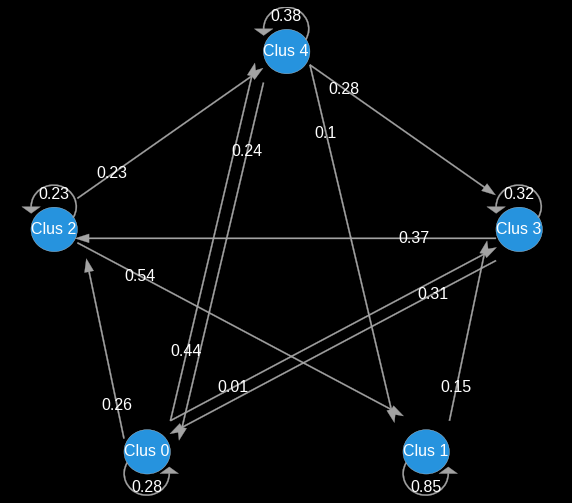
6. Analyse des parcours clients
Nous cherchons à visualiser les parcours clients en fonction des segments pour ce faire nous utilisons notre outil de visualisation interne des parcours clients par segment. Nous cherchons à déterminer les parcours représentatifs de chaque segment. Ces analyses nous permettent de définir les moments clés et produits clés à chaque étape du parcours clients et ainsi donner des pistes .
Conclusion
Notre approche de la segmentation marketing se veut interprétable. Pour réaliser une segmentation marketing réussie, il faut bien évidemment maîtriser les méthodologies data science, mais il ne faut pas perdre de vue l’objectif métier. Cela signifie qu’il faut prendre en compte les contraintes métiers dans les algorithmes, s’assurer de l’interprétabilité mais aussi donner aux métiers les moyens d’activer la segmentation en qualifiant et analysant précisément les comportements clients. Après une segmentation data driven, nous devons être capable d'identifier et de définir les caractéristiques et enjeux des différents segments et les moments clés de son cycle de vie. A partir de ces analyses, les équipes marketing pourront construire des personae et mettre en place une stratégie marketing dédiée par segment s’appuyant sur une connaissance approfondie des parcours clients et de leurs caractéristiques.


