Use Anchor to better understand your Machine Learning model
Interpretability is becoming more and more important in AI. Here is a method to better explain models with ANCHOR.
In the last ten years, advances in the field of Artificial Intelligence have been impressive with many achievements such as the defeat of the best Go players against AlphaGo, the AI-based computer program. To solve these difficult problems, the resolution algorithms are becoming more and more sophisticated and complex: therefore, the interpretability of Deep Learning models is difficult. Moreover, that complexity can be an obstacle to the use of deep learning algorithms (business and operational users will not understand the algorithm and, at the end, will not adhere to the methodology) and easily lead to biases and even ethical problems (e.g. discrimination).
The notion of interpretability is thus important: by using specific models or interpretability methods, it is possible to make the results but also the problem much more understandable and easily explainable for human beings. Potential biases are more easily detectable and avoidable. In addition, with the passing of laws such as the "Code of Federal Regulations" in the USA or the "GDPR" in the European Union, the "Right to Explanation" becomes more and more important and even mandatory in the coming years (for the moment, some juridic vacuum exist about that subject): this means that if an AI model is used with the data of a third person, then that same person can ask why the model made that prediction.
In this article, we aim to introduce the concept of interpretability and particularly the Anchor method, an agnostic-model, to understand your model and your predictions.
About AI interpretability
For the moment, there is no mathematical or scientific definition of “Interpretability”. Sometimes, that notion is also confused with the word “Explainability”. Generally speaking, if those two notions are distinct, “Interpretability” is equivalent to answering the question "How is this result obtained?" and “Explainability” to the question "Why is this result obtained?". Thereafter, we will not differentiate between those two notions in the article and we only focus on the question “How ?”.
The level of interpretability is not uniform across all predictive and classification methods. On the one hand, linear regression and logistic models are considered as easily interpretable: the prediction results can be explained directly with the model, but those algorithms could not be that efficient for some problems. On the other hand, with the multiplicity of dimensions and a large amount of data, the algorithms become more and more complex (such as the neural networks, ...) and, consequently, the performances of the predictive models are increasing. However, interpreting those results becomes a tough task. The interpretation will require post hoc methods such LIME [1] or SHAP [2].
Level of interpretability and performance according the type of models

Concerning the methods of interpretability, there are several and can be classified according to criteria:
- “Intrinsic” (directly from the model) or “Post hoc” (after the prediction)
- “Model agnostic” (applicable to all types of models) or “Model specific” (applicable to some types of models)
- “Global” (the interpretation concerns all the points) or “Local” (the interpretation concerns only one or a few points)
For example, “LIME” and “Kernel SHAP” (an implementation of SHAP) are interpretation methods considered “Local”, “Post hoc” and "Model agnostic"
After creating LIME, its conceptor builds Anchor
Anchor is another interpretation method for classification models created by Marco Tulio Ribeiro, the inventor of LIME. With the same philosophy as LIME, Anchor deploys a perturbation-based method to create local explanations. It can explain the individual predictions of any "black box" model. That method is therefore considered “Local”, “Post hoc” and "Model agnostic". Moreover, compared to other interpretability methods such as LIME or SHAP, those interpretations of Anchor are much closer to human understanding with prediction rules to know how the model obtained the result.
Concerning the generation of rules, this process is based on successive iterations on potential rule candidates. Each iteration selects the best candidates and pertubates them by extending the rules with new features. The loop ends when the rule meets the conditions on the accuracy. If you want more information about the generation process, the article “Anchors: high-precision model-agnostic explanations” published in 2018 [3] describes the entire process in detail.
Different implementation of Anchor
The Anchor method has been implemented and is available on different programming languages:
- In Python: https://github.com/marcotcr/anchor
- In R: https://github.com/viadee/anchorsOnR
- In Java: https://github.com/viadee/javaAnchorExplainer
Those different modules propose to interpret the models trained on tabular or textual classification problems. You can also find examples of Anchor use on notebooks [4] and [5].
To test the method (in Python), we focus on the "Red Wine Quality [6]" dataset with physicochemical inputs and quality output.
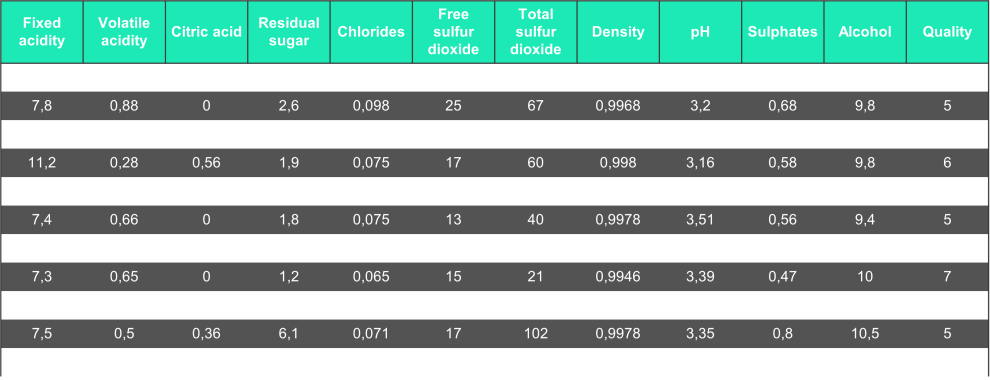
Then, we train a Random Forest model to predict the quality output.
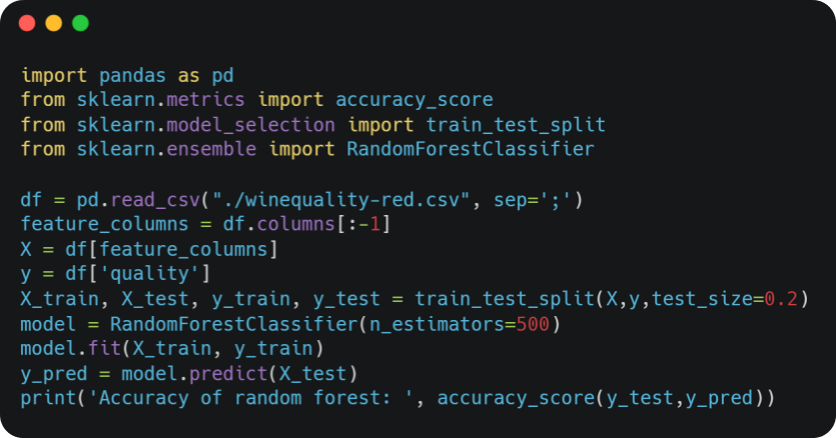
We obtain the following result:
Accuracy of random forest: 0.709375
With that dataset and that trained model, we can apply the Anchor method and we get the following rule for a random point:
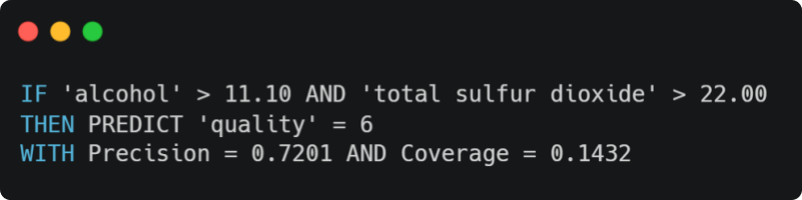
In addition to the generated prediction rule, two metrics are also returned that provide insight about the quality and the relevance of the rule:
- Precision: the relative number of correct predictions. In the previous result, the rule was correct 7.2 times on average for 10 predictions.
Coverage: the “perturbation space” (ie, the anchor’s probability of applying to its “neighbors”) or the relative number of points generated by the “perturbation” that follow the rule. Generally, the more variables the rule contains, the lower the coverage
Exploration of models with Anchor method
From that interpretability method, it is quite possible to explore and understand any prediction model. To do so, we will iterate the Anchor method over many points of the dataset. The algorithm takes as input a minimal precision threshold for Anchor method and a proportion of points of the dataset implied by all the rules and as output, the list of all the rules. About the exploration, the principle is the following:
- Get a random point in the dataset
- Apply Anchor method on that point
- Remove the points affected by the rule from the dataset
- Save the rule
- Repeat from step 1 until the proportion of points remaining is less than the input
By applying the exploration algorithm described above with a minimum accuracy threshold of 0.7 and by traversing at least 80% of the dataset, we generate more than thirty prediction rules. Here are some of them:
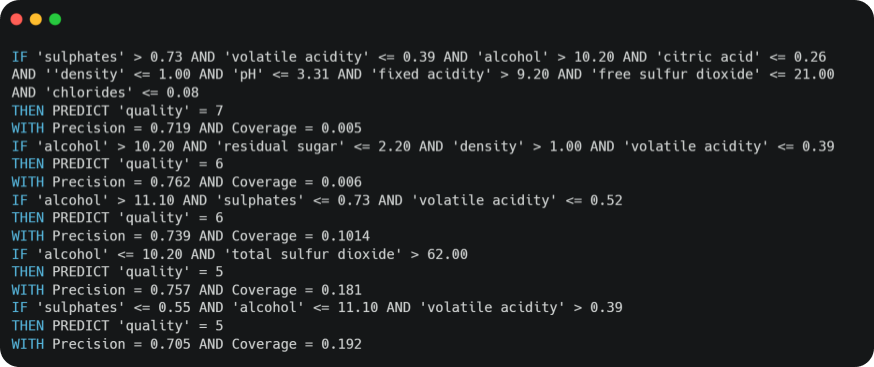
To check the relevance of those rules, the variables involved in the rules are compared directly with the results of a Feature Importance [5]. First, we count the number of occurrences of each variable in the rules.
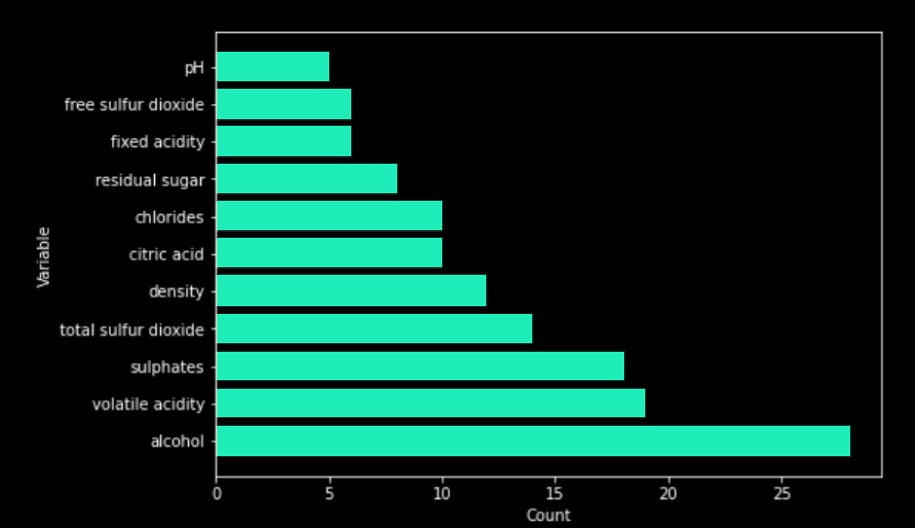
Then, secondly, we run a Feature Importance algorithm [5] on the Random Forest.

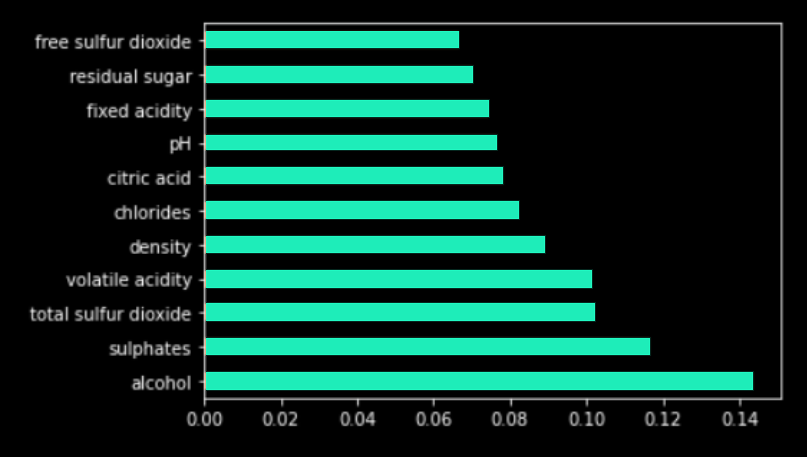
We notice that the variables the most present in the rules also have an important value in the results of feature importance (and vice versa). From those results, this confirms that the generated rules have meaning and are relevant in the understanding of the model. In the context of the "GDPR" or the "Code of Federal Regulations", that method allows to find the most important variables but also to know how they impact the model with simple and understandable explanations for all stakeholders.
With that exploration method, transparency and understanding of the model are enhanced. We can more easily involve the different operational teams in the conception of the ML model (and not only upstream) but also in its control after its deploiement: anyone without technical skills in the operation team can review the predictions from the generated rules.
We have only explored a tiny part of the XAI (or “Explainable AI”) with the Anchor method. There are other approaches different from the one discussed previously or from the more known ones like Lime or SHAP. For example, Microsoft Research has recently developed a new predictive model, Explainable Boosting Machine or EBM [8], that can "produce exact explanations".
At Sia Partners we got used to implementing Anchor, helping us to better monitor our ethical approach to our algorithms. If you want to know more about our AI solutions, check out our Heka website.
References
[1] Ribeiro, Marco Tulio and Singh, Sameer and Guestrin, Carlos. "Why Should I Trust You?": Explaining the Predictions of Any Classifier (2016)
[2] Lundberg, Scott M., and Su-In Lee. “A unified approach to interpreting model predictions.” Advances in Neural Information Processing Systems (2017)
[3] Ribeiro, Marco Tulio and Singh, Sameer and Guestrin, Carlos. “Anchors: high-precision model-agnostic explanations”. AAAI Conference on Artificial Intelligence (AAAI), 2018
[4] https://github.com/marcotcr/anchor/blob/master/notebooks/Anchor%20on%20tabular%20data.ipynb
[5] https://github.com/marcotcr/anchor/blob/master/notebooks/Anchor%20for%20text.ipynb
[6] https://archive.ics.uci.edu/ml/datasets/wine+quality
[7] Fisher, Aaron, Cynthia Rudin, and Francesca Dominici. “All models are wrong, but many are useful: Learning a variable’s importance by studying an entire class of prediction models simultaneously.” (2018) http://arxiv.org/abs/1801.01489
[8] Nori, Harsha and Jenkins, Samuel and Koch, Paul and Caruana, Rich “InterpretML: A Unified Framework for Machine Learning Interpretability” (2019)


