Utiliser Anchor pour mieux comprendre votre modèle de Machine Learning
L'interprétabilité devient de plus en plus importante en matière d'IA. Découvrez une méthode permettant de mieux appréhender ces modèles avec ANCHOR.
Au cours des dix dernières années, les avancées dans le domaine de l'intelligence artificielle ont été fulgurantes avec la réalisation de nombreuses prouesses comme la défaite des meilleurs joueurs de Go face à AlphaGo, un programme informatique se basant sur l'IA. Pour résoudre ces problèmes compliqués, les algorithmes de résolution sont devenus de plus en plus sophistiqués et complexes : interpréter ces modèles de Deep Learning est donc une tâche difficile. De plus, cette complexité peut constituer un obstacle à l'utilisation du Deep Learning (les utilisateurs opérationnels et non techniques auront des grandes difficultés à comprendre l'algorithme et ne vont pas finalement adhérer à la méthodologie) et peut facilement conduire à des biais, voire à des problèmes éthiques (par exemple, la discrimination).
L’interprétabilité est ainsi une notion essentielle : en utilisant des modèles spécifiques ou des méthodes d'interprétabilité, il est possible de rendre les résultats mais également le problème beaucoup plus compréhensibles et explicables pour les humains. Les biais potentiels sont plus facilement détectables et donc évitables. En outre, avec l'adoption de nouvelles lois telles que le "Code of Federal Regulations" aux États-Unis ou le "RGPD" dans l'Union européenne, le "Droit à l'explication" commence à prendre de l’importance et pourrait devenir obligatoire dans les années à venir (pour le moment, un vide juridique existe à ce sujet) : en d’autres termes, si un modèle d'IA est utilisé avec les données d'une tierce personne, celle-ci peut demander comment les résultats de prédiction, lui concernant, ont été obtenus.
Dans cet article, nous allons introduire le concept d'interprétabilité et, en particulier, la méthode d’Anchor qui est agnostique vis-à-vis du modèle pour mieux comprendre votre modèle et vos prédictions.
À propos de l'interprétabilité de l'IA
Actuellement, il n'existe pas de définition mathématique ou scientifique de l'Interprétabilité. Parfois, cette notion est également confondue avec celle de l’Explicabilité. D'une manière générale, si ces deux notions sont distinctes, Interprétabilité est équivalent à répondre à la question "Comment ce résultat est-il obtenu ?" et Explicabilité à la question "Pourquoi ce résultat est-il obtenu ?". Par la suite, nous ne ferons pas de distinction entre ces deux notions dans l'article et nous nous concentrerons uniquement sur la question "Comment ?".
Sur l’ensemble des méthodes prédictives et de classification, le niveau d'interprétabilité n'est pas uniforme. D'une part, les régressions linéaires et les modèles logistiques sont considérés comme facilement interprétables : les résultats des prédictions sont obtenus directement par le modèle, mais ces algorithmes ne sont pas efficaces pour certaines classes de problèmes. D'autre part, avec la multiplicité des dimensions et des données, les algorithmes deviennent progressivement plus complexes (comme les réseaux de neurones, ...) et, par conséquent, les performances de ces modèles prédictifs augmentent. Cependant, interpréter ces résultats est une tâche difficile et l'interprétation nécessitera donc des méthodes post hoc telles que LIME [1] ou SHAP [2].
Niveau d'interprétabilité et de performance en fonction du type de modèles

Concernant les méthodes d'interprétabilité, plusieurs approches existent et peuvent être classées selon plusieurs critères :
- "Intrinsèque" (directement issue du modèle) ou "Post hoc" (après la prédiction).
- "Agnostique vis-à-vis du modèle" / “Model Agnostic” (applicable à tous les types de modèles) ou "Spécifique au modèle" / “Model specific” (applicable uniquement à certains types de modèles).
- "Global" (l'interprétation concerne tous les points) ou "Local" (l'interprétation ne concerne uniquement qu'un ou quelques points).
Par exemple, "LIME" et "Kernel SHAP" (une implémentation de SHAP) sont des méthodes d'interprétation considérées comme "locales", "Post hoc" et "agnostiques vis-à-vis du modèle".
Après avoir créé LIME, son concepteur conçoit Anchor
Anchor est une autre méthode d'interprétation des modèles de classification créée par Marco Tulio Ribeiro, le créateur de LIME. En se basant sur la même démarche que LIME, Anchor crée des explications locales en perturbant le point à expliquer : elle peut ainsi expliquer les prédictions individuelles des modèles de type "boîte noire". Cette méthode est donc considérée comme "locale", "Post hoc" et "agnostique vis-à-vis du modèle". De plus, par rapport à d'autres méthodes comme LIME ou SHAP, les interprétations obtenues par Anchor sont beaucoup plus proches de la compréhension humaine avec des règles de prédiction simples.
Concernant la génération des règles, ce processus s'appuie sur des itérations successives. Chaque itération sélectionne les meilleures règles et les perturbe en ajoutant de nouveaux attributs. La boucle se termine lorsque la règle finale remplit la condition de précision. Si vous souhaitez plus d'informations sur le processus de génération, l'article "Anchors: high-precision model-agnostic explanations " publié en 2018 [3] décrit en détail l'ensemble du processus.
Différentes implémentations de la méthode d’Anchor
La méthode d’Anchor est disponible sur plusieurs langages de programmation :
- Sur Python: https://github.com/marcotcr/anchor
- Sur R: https://github.com/viadee/anchorsOnR
- Sur Java: https://github.com/viadee/javaAnchorExplainer
Ces différents modules proposent d'interpréter les modèles entrainés sur des problèmes de classification tabulaire ou textuelle. Vous pouvez aussi trouver des exemples d'utilisation d'Anchor sur les notebooks [4] et [5].
Pour tester la méthode (en Python), nous nous concentrons sur le jeu de données "Red Wine Quality [6]" avec en entrées les caractéristiques physico-chimiques du vin et en sortie sa qualité.
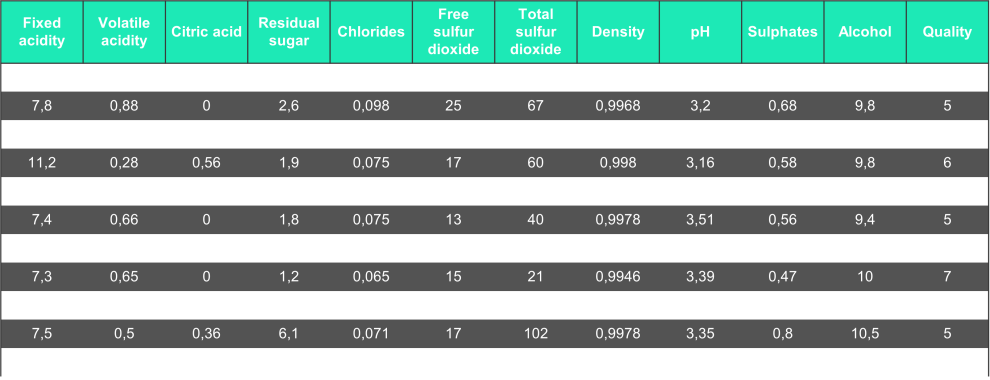
Ensuite, nous entraînons un modèle de type “Random Forest” pour prédire la qualité du vin.
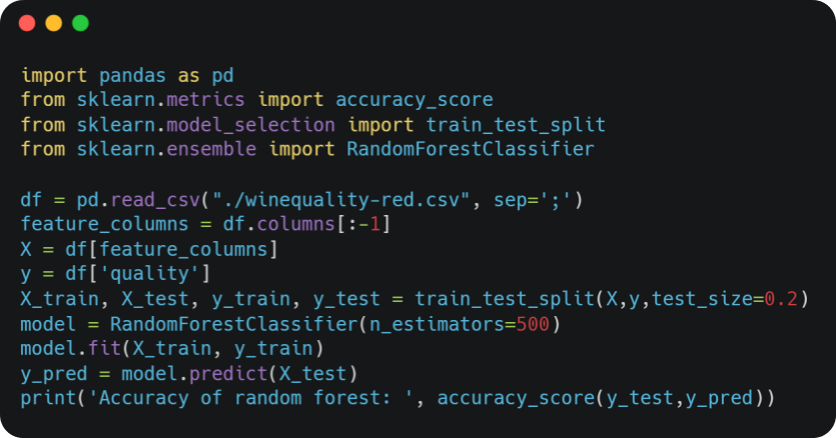
Nous obtenons le résultat suivant : Accuracy of random forest: 0.709375
Avec ces données et ce modèle entraîné, nous pouvons appliquer la méthode d’Anchor et nous obtenons la règle suivante pour un point pris aléatoirement :
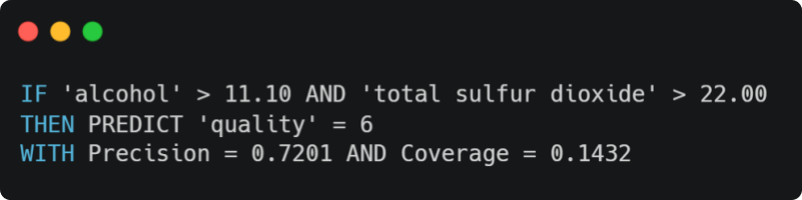
En plus de l’explication générée, deux autres métriques sont également retournées qui donnent un aperçu de la pertinence de la règle :
- Précision (Precision) : le nombre relatif de prédictions correctes. Dans le résultat précédent, la règle était, en moyenne, correcte 7.2 fois pour 10 prédictions.
- Couverture (Coverage) : l'espace de perturbation (c’est-à-dire, la probabilité que la règle s'applique aussi à ses "voisins") ou le nombre relatif de points générés par la "perturbation" qui suivent la règle. En général, plus la règle contient de variables, plus la couverture est faible.
Exploration des modèles avec la méthode d’Anchor
A partir de cette méthode d'interprétabilité, il est possible d'explorer et de comprendre n'importe quel modèle de prédiction. Pour ce faire, nous allons réitérer la méthode d’Anchor sur de nombreux points du jeu de données. L'algorithme prend en entrée un niveau minimal de précision (pour la méthode d’Anchor) et la proportion de points concernées par l’ensemble des règles et, en sortie, la liste de toutes les règles. Le principe de cet exploration est le suivant :
- Sélectionner aléatoirement un point dans le jeu de données.
- Appliquer la méthode d’Anchor sur ce même point
- Retirer les points affectés par la règle générée du jeu de données
- Sauvegarder la règle
- Retourner à l'étape 1 jusqu'à ce que la proportion de points restants soit inférieure à la valeur indiquée en entrée
En appliquant l'algorithme d'exploration décrit ci-dessus avec un seuil de précision minimum à 0,7 et en parcourant au moins 80% des données, nous générons plus d’une trentaine de règles de prédiction. En voici quelques-unes :
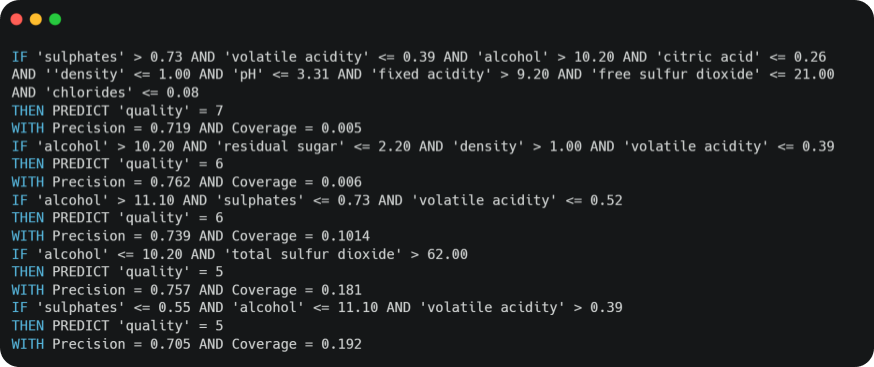
Pour vérifier la pertinence de ces règles, les variables impliquées dans les règles sont directement comparées avec les résultats d'une Feature Importance. Tout d'abord, nous comptons le nombre d'occurrences des variables dans chacune des règles.
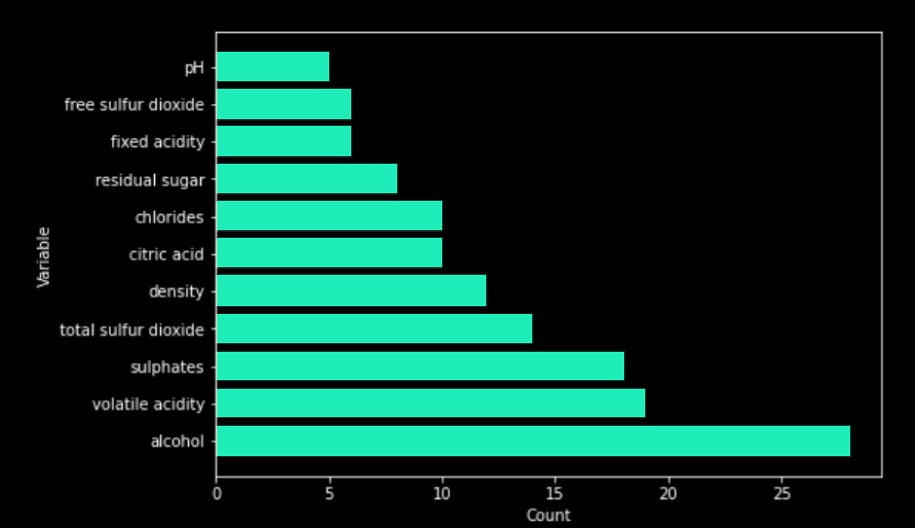
Puis, dans un deuxième temps, nous exécutons un algorithme de Feature Importance [5] sur le modèle “Random Forest”.

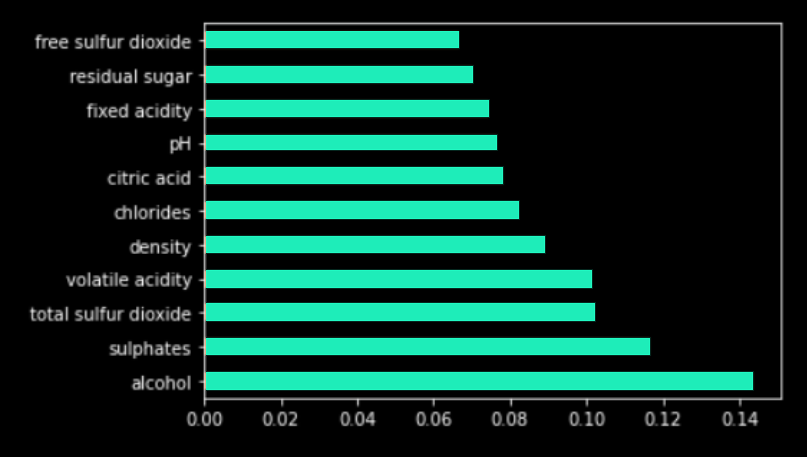
On remarque que les variables les plus présentes dans les règles ont également une valeur importante dans les résultats de Feature Importance (et vice versa). A partir de ces résultats, cela confirme que les règles générées ont un sens et sont pertinentes dans la compréhension du modèle. Dans le contexte des lois "RGPD" ou de la "Code of Federal Regulations", cette méthode permet de trouver les variables les plus importantes mais aussi de savoir comment elles impactent le modèle avec des explications simples et compréhensibles pour l’ensemble des parties prenantes.
Avec cette méthode d'exploration, la transparence et la compréhension du modèle sont améliorées. Nous pouvons plus facilement impliquer les différentes équipes opérationnelles dans la conception du modèle de ML (et pas seulement en amont) mais aussi dans son contrôle après son déploiement : toute personne de l'équipe opérationnelle sans compétences techniques a la capacité de vérifier les prédictions des règles générées.
Avec cet article, nous n'avons exploré qu'une infime partie de l’XAI (ou "Explainable AI") avec la méthode d’Anchor. Il existe d'autres approches différentes de celle présentée précédemment ou des plus connues comme Lime ou SHAP. Par exemple, Microsoft Research a récemment développé un nouveau modèle prédictif, Explainable Boosting Machine ou EBM [8], qui peut "produire des explications exactes".
A Sia Partners, nous avons pris l'habitude d'utiliser Anchor, ce qui nous aide à mieux contrôler notre approche éthique de nos algorithmes. Si vous souhaitez en savoir plus sur nos solutions d'IA, consultez notre site web Heka.
Références
[1] Ribeiro, Marco Tulio and Singh, Sameer and Guestrin, Carlos. "Why Should I Trust You?": Explaining the Predictions of Any Classifier (2016)
[2] Lundberg, Scott M., and Su-In Lee. “A unified approach to interpreting model predictions.” Advances in Neural Information Processing Systems (2017)
[3] Ribeiro, Marco Tulio and Singh, Sameer and Guestrin, Carlos. “Anchors: high-precision model-agnostic explanations”. AAAI Conference on Artificial Intelligence (AAAI), 2018
[4] https://github.com/marcotcr/anchor/blob/master/notebooks/Anchor%20on%20tabular%20data.ipynb
[5] https://github.com/marcotcr/anchor/blob/master/notebooks/Anchor%20for%20text.ipynb
[6] https://archive.ics.uci.edu/ml/datasets/wine+quality
[7] Fisher, Aaron, Cynthia Rudin, and Francesca Dominici. “All models are wrong, but many are useful: Learning a variable’s importance by studying an entire class of prediction models simultaneously.” (2018) http://arxiv.org/abs/1801.01489
[8] Nori, Harsha and Jenkins, Samuel and Koch, Paul and Caruana, Rich “InterpretML: A Unified Framework for Machine Learning Interpretability” (2019)


