Auto encodeur et valeurs SHAP : Détection et interprétation
La détection d'anomalies est le processus d'identification de modèles irréguliers dans les données. Cela va de la détection des fraudes à la maintenance prédictive en passant par la détection du taux de désabonnement. Les gammes d'algorithmes d'apprentissage automatique abordent ces problématiques.
La plupart des algorithmes de détection d'anomalies par apprentissage automatique, tels que Isolation Forest, Local Outlier Factor ou Autoencoder, génèrent un score de probabilité pour chaque point de données d'être une anomalie. La distinction entre les valeurs normales et les anomalies se fait alors la plupart du temps par le choix d'un seuil.
Ces algorithmes peuvent être très efficaces et permettre aux experts de gagner un temps précieux pour inspecter un ensemble de données. Cependant, l'utilisation d'algorithmes d'apprentissage automatique présente un inconvénient majeur : La plupart d'entre eux fonctionnent comme une boîte noire et ne donnent aucune information sur la raison pour laquelle une observation est considérée comme aberrante. Dans un contexte commercial, la confiance des experts et des entreprises dans les algorithmes d'apprentissage automatique dépend fortement de leur capacité à expliquer leurs résultats.
Nous présenterons et illustrerons ici une méthode décrite dans le document Explaining Anomalies Detected by Autoencoders Using SHAP, de l'université du Negev, en Israël [1]. Cette méthode repose sur l'utilisation d'autoencodeurs et d'un cadre que nous présenterons, SHAP.
Qu'est-ce qu'un autoencodeur et comment l'utiliser pour détecter des anomalies ?
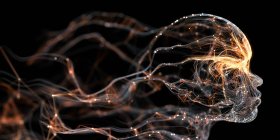
Les autoencodeurs sont un type de réseau neuronal artificiel introduit dans les années 1980 pour répondre aux défis de la réduction de la dimensionnalité. Un autoencodeur vise à apprendre la représentation des données d'entrée et tente de produire des valeurs cibles égales à ses entrées : Il représente les données dans une dimensionnalité inférieure, dans un espace appelé espace latent, qui agit comme un goulot d'étranglement (action d'encodage) et reconstruit les données dans la dimensionnalité d'origine (action de décodage). Sur la base de l'entrée, l'autoencodeur construit l'espace latent de telle sorte que la sortie de l'autoencodeur est similaire à l'entrée et que le modèle intégré créé lors de l'encodage représente bien les instances normales. En revanche, les anomalies ne sont pas bien reconstruites et présentent un taux d'erreur de reconstruction élevé, de sorte que les anomalies sont découvertes au cours du processus de codage et de décodage des instances.
En tant que réseau neuronal classique, l'autoencodeur ajuste ses poids par descente de gradient, afin de minimiser une fonction. Dans un réseau neuronal de classification supervisée, cette fonction est la distance/erreur entre les prédictions et les étiquettes. Dans le cas de l'autoencodeur, l'erreur est l'erreur de reconstruction, qui mesure les différences entre l'entrée originale et la reconstruction.
Que sont les valeurs SHAP ?
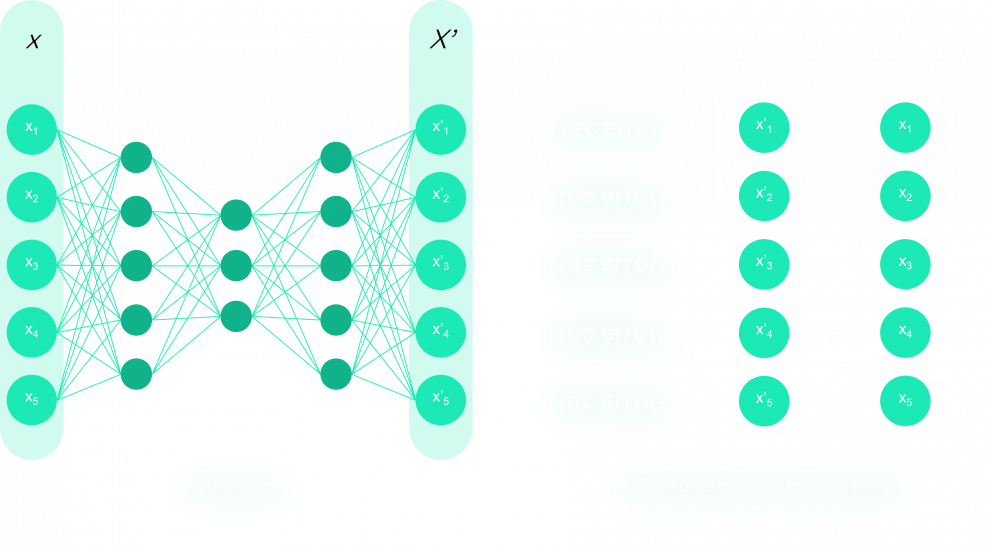
Comme indiqué dans l'introduction, les algorithmes d'apprentissage automatique présentent un inconvénient majeur : Les prédictions sont ininterprétables. Ils fonctionnent comme une boîte noire, et le fait de ne pas pouvoir comprendre les résultats produits n'aide pas à l'adoption de ces modèles dans de nombreux secteurs, où les causes sont souvent plus importantes que les résultats eux-mêmes. Un type d'outil a donc été développé pour permettre de comprendre les décisions des modèles. Le SHAP Value est un outil parmi d'autres comme LIME, DeepLIFT, InterpretML, ou ELI5 pour expliquer les résultats d'un modèle d'apprentissage automatique.
Cet outil est issu de la théorie des jeux : Lloyd Shapley a trouvé un concept de solution en 1953, afin de calculer la contribution de chaque joueur dans un jeu coopératif. Nous définissons les variables suivantes :
- le jeu a P joueurs
- S est un sous-ensemble des P joueurs
- v(X) est la valeur cumulée de l'ensemble des X joueurs
- i est un joueur qui ne fait pas partie des joueurs S
La valeur du groupe S + i est donc v(S+ i). Si nous voulons calculer la valeur de i, v(i) = v(S∪i) - v(S). Pour avoir une bonne estimation de la valeur marginale, nous prenons la moyenne de la contribution sur les différentes permutations possibles des joueurs.
Cette méthode de visualisation de la contribution des caractéristiques est adaptée aux modèles d'arbres basés, dans lesquels les variables entrent dans le modèle d'apprentissage automatique de manière séquentielle dans les arbres du modèle. Étant donné le nombre d'arbres et de branches, nous devrions observer toutes les permutations des caractéristiques. Pour les modèles autres que les arbres, SHAP propose une variante de l'algorithme principal, adaptée aux spécificités du modèle, comme GradientExplainer, LinearExplainer, DeepExplainer...
Nous utiliserons dans la partie suivante l'implémentation SHAP (Shapley Additive exPlanations) de [2].
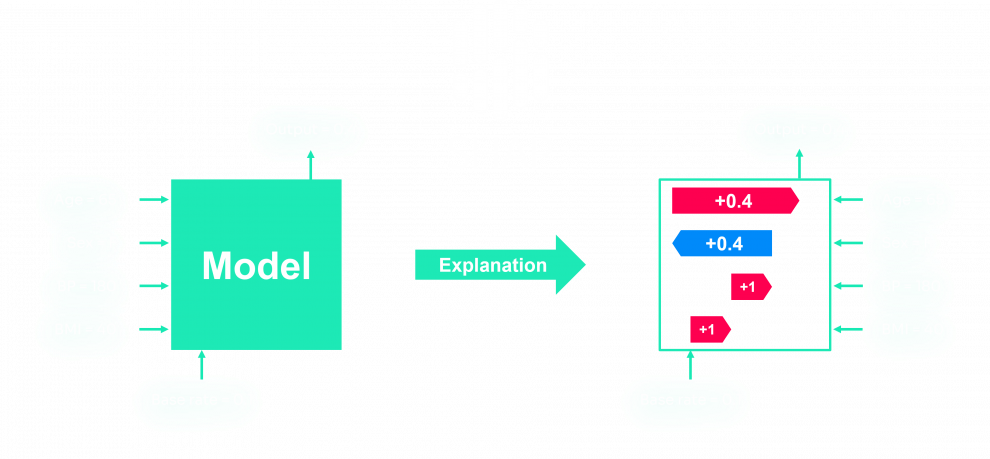
Comme nous utilisons des autoencodeurs, un modèle d'apprentissage profond, nous utiliserons DeepExplainer, basé sur la publication Learning Important Features Through Propagating Activation Differences (Apprendre les caractéristiques importantes en propageant les différences d'activation).
Comment interpréter les anomalies à l'aide d'Autoencoder et de SHAP ?
Tout d'abord, nous utilisons un autoencodeur simple que nous avons construit à l'aide de keras.
L'autoencodeur à utiliser peut avoir une structure différente. Cependant, il est important de conserver la première couche cachée appelée hid_layer1, puisque nous modifierons ensuite les poids de cette couche.
Ensuite, nous utilisons cet autoencodeur pour déterminer l'erreur de reconstruction par observation, et pour chaque observation, nous classons les caractéristiques en fonction de leur erreur de reconstruction :
Et nous sélectionnons les m caractéristiques qui ont l'erreur la plus élevée. Nous choisissons m de manière à ce que la somme des erreurs des caractéristiques représente une bonne partie de l'erreur de reconstruction totale (80 % par exemple).
Ces caractéristiques sont stockées dans topMfeatures. Ensuite, pour chaque caractéristique de topMfeatures, nous utiliserons SHAP pour déterminer quelles caractéristiques contribuent à l'erreur de reconstruction et quelles caractéristiques compensent l'erreur de reconstruction.
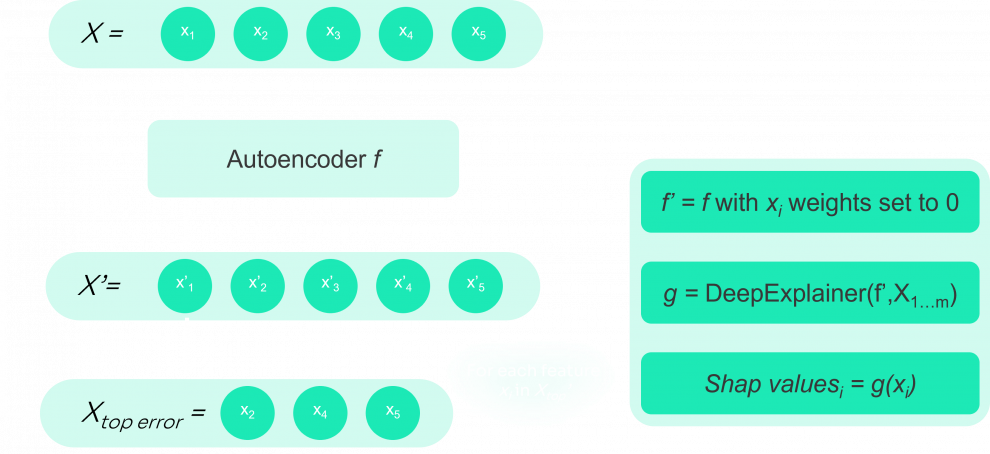
Pour ce faire, nous supprimons d'abord les poids associés à la caractéristique inspectée dans le modèle, puisque nous ne voulons pas connaître l'effet de la caractéristique sur sa reconstruction. Ensuite, nous utilisons DeepExplainer SHAP pour obtenir les valeurs SHAP et les stocker. L'algorithme de ce processus est présenté ci-dessous :
l'élimination des poids pour l'élément actuel
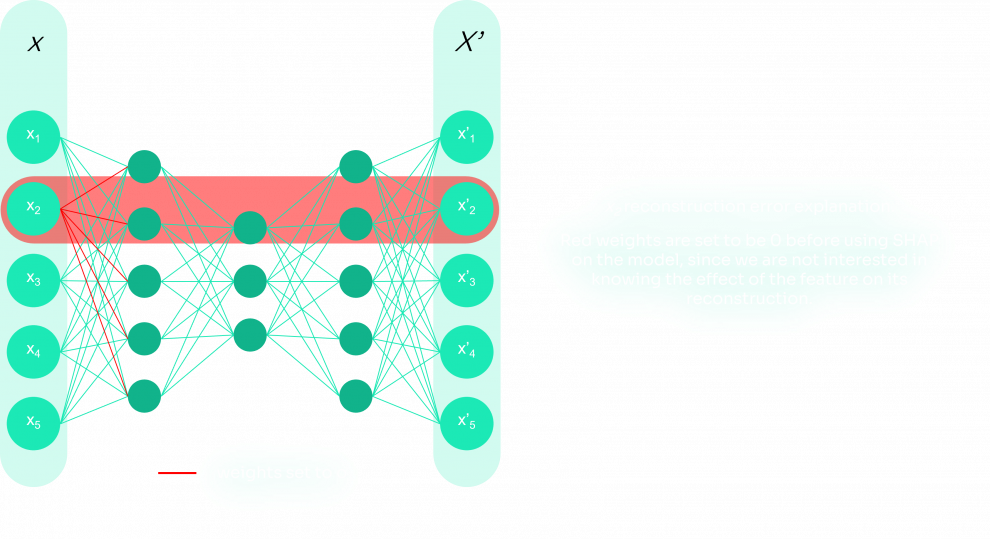
représentation de l'algorithme
Pour tester cette méthode, nous avons utilisé un ensemble de données de détection de la fraude par carte de crédit provenant de Kaggle [4]. Cet ensemble de données contient des transactions effectuées par cartes de crédit pendant deux jours en septembre 2013 par des détenteurs de cartes européens. Il contient 30 variables d'entrée numériques qui sont le résultat d'une transformation ACP. Pour des raisons de confidentialité, nous ne disposons pas d'informations de base sur les données. Les caractéristiques V1, V2, ... V28 sont les composantes principales obtenues avec l'ACP, et les seules caractéristiques qui n'ont pas été transformées avec l'ACP sont 'Time' et 'Amount'.
Tout d'abord, nous devons distinguer les anomalies des points de données normaux. Traditionnellement, nous choisissons un seuil qui limite autant que possible le nombre de faux positifs et de vrais négatifs. Mais nous pouvons également utiliser une valeur de score Z modifiée pour identifier les valeurs aberrantes, comme présenté dans [4]. C'est cette méthode que nous utiliserons.
En utilisant cette méthode, nous avons trouvé 2 223 valeurs aberrantes sur un total de 84 807 transactions.
Voici un exemple du résultat que nous avons obtenu pour une anomalie détectée : en rouge les valeurs contribuant à l'anomalie, en bleu les valeurs compensant l'anomalie. Nous avons utilisé la méthode force_plot de SHAP pour obtenir le tracé.
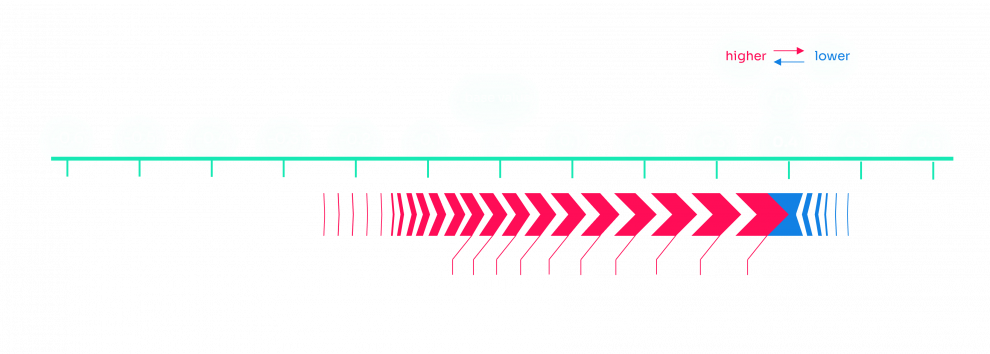
Malheureusement, comme nous n'avons pas d'explication sur la signification de chaque caractéristique, nous ne pouvons pas interpréter les résultats que nous avons obtenus. Cependant, dans un cas d'utilisation professionnelle, il est noté dans [1] que le retour d'information obtenu de la part des experts du domaine sur les explications des anomalies était positif.
Chez Sia Partners, nous avons travaillé et travaillons sur plusieurs missions de détection d'anomalies, telles que la détection d'anomalies dans les données clients, dans les mesures de concentration de chlore, etc...
Nous travaillons également sur la conception, le déploiement et la gestion d'applications basées sur l'IA, à travers notre écosystème Heka. Si vous souhaitez en savoir plus sur nos solutions d'IA, consultez notre site web Heka.