Prédire le churn client avec l’IA
Grâce à l’exploitation des données et d’outils de Machine Learning, les entreprises peuvent améliorer de façon significative leurs activités. Le Machine Learning est un champ d'étude de l'intelligence artificielle qui permet de donner à une IA la capacité d’« apprendre » à partir de données.
Dans le domaine du marketing, le scoring est une technique qui permet d'affecter un score à un client ou prospect. Le score obtenu traduit généralement la probabilité qu'un individu appartienne à la cible recherchée ou réponde à une sollicitation marketing.
De nombreuses techniques de scoring peuvent être utilisées en marketing selon les contextes, la finalité et les données disponibles (lead scoring, scoring risque, scoring prédictif…) Par exemple, le scoring prédictif peut être utilisé pour identifier les clients avec un risque d'attrition* élevé. On parle alors de prédiction du churn.
* Churn en anglais. Ce terme désigne la perte de clientèle ou d'abonnés.
Présentation du cas d’usage ?
Afin de présenter une approche complète d’une prédiction de churn, nous utiliserons les données du service de streaming musical KKBOX pour construire un modèle prédictif. Il est à noter que pour KKBOX un client churn est un client qui n’a pas renouvelé d’abonnement dans les 30 jours suivant la date d’expiration de son dernier abonnement.
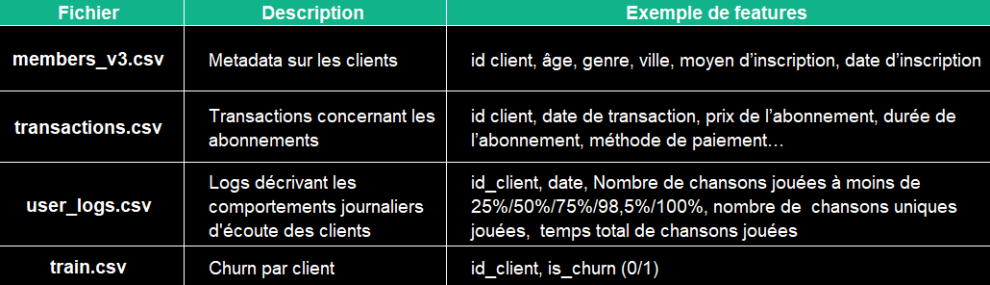
Nous avons 4 fichiers de données à notre disposition pour la prédiction :
L’approche pour ce cas d’usage commencera par une analyse exploratoire (qualité des données & exploration), avant de préparer le dataset (pre-processing, feature engineering) pour lancer la modélisation (entraînement, test & validation des modèles) et interpréter les résultats.
I. Qualité des données & analyse exploratoire
A. Qualité des données
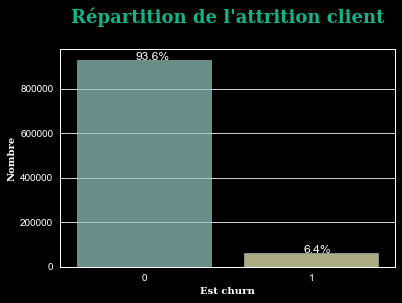
L’analyse de la qualité des données permet de mesurer l'état des données avec notamment la détection d’anomalies, la complétude des données et l’évaluation de la pertinence des données.
Cette étape est primordiale dans tout projet Data. Elle consiste tout d’abord au chargement des différents datasets et à la visualisation des informations principales. Nous souhaitons également détecter les anomalies afin de décider de la meilleure technique pour redresser la donnée.
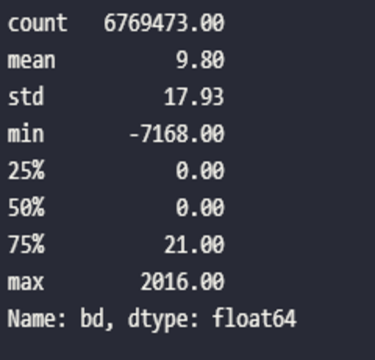
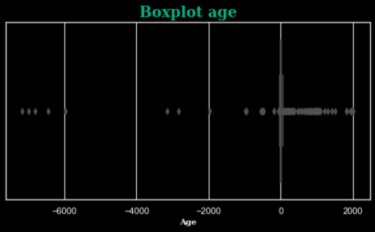
Dans notre cas, en regardant par exemple l’âge des clients, nous pouvons constater qu’il y a beaucoup d'outliers (âges allant de -7168 à 2016 ans). Nous utiliserons une méthode de Machine Learning afin de redresser ces données.
?Focus Méthodo: Détection des outliers
La détection d’outliers peut se faire à l’aide de plusieurs méthodes :
-
Le tri. Trier les données permet d’identifier directement les valeurs extrêmes.
-
L’écart interquartile. L’utilisation de l’écart interquartile permet de créer des bornes autour des données, puis de définir les valeurs aberrantes comme étant toutes les valeurs qui se situent en dehors de ces bornes.
-
Convertir les données en z-score. En règle générale, les valeurs dont le z-score est supérieur à 3 ou inférieur à -3 sont considérées comme des valeurs aberrantes.
B. Analyse exploratoire
Pour l’analyse exploratoire nous vous recommandons cet article medium répertoriant plusieurs méthodes pertinentes.
L’analyse exploratoire est une étape importante pour la modélisation car elle permet de comprendre les données, en sortir des enseignements métiers qui enrichiront la préparation du dataset et d’initier une première sélection de variables pertinentes.
II. Préparation des données
Transformation des données
Cette étape permet de transformer les données en un format qui pourra être traité facilement par un modèle.

?Focus Méthodo: La multi colinéarité
-
La multi colinéarité se produit lorsque deux ou plusieurs variables sont fortement corrélées. Elle mène vers de mauvais résultats pour certains modèles comme les modèles linéaires.
-
Normaliser les features permet de les décorréler. Selon le cas d’usage, l’agrégation peut se faire par la moyenne, médiane, somme…
import seaborn as sns
import matplotlib.pyplot as plt
import numpy as np
corr = customers.corr()
mask = np.zeros_like(corr)
mask[np.triu_indices_from(mask)]= True
fig, ax = plt.subplots(figsize=(42,20))
ax = sns.heatmap(corr, vmin=-1, vmax=1, fmt=".2f", annot_kws={'size':8}, mask=mask)
plt.title(f"Heatmap of linear correlations\n", fontdict=font_title)
plt.show()
B. Preprocessing
Selon le modèle que vous souhaitez utiliser (cf partie III), une fois les variables utiles sélectionnées et le fichier préparé, il est nécessaire d’ajouter une étape de preprocessing.
Par exemple, si le modèle ne prend en compte que les variables numériques, il faut transformer les variables catégorielles (encoding). On peut par exemple utiliser le one-hot encoding qui consiste à coder chaque variable catégorielle avec différentes variables booléennes indiquant si une catégorie est présente dans une observation.
city = pd.get_dummies(X.city, prefix='city')
X = X.join(city)
Pour les variables numériques, il peut être nécessaire de les standardiser pour ne pas biaiser l’algorithme si deux variables ne sont pas à la même échelle. On peut utiliser le preprocessor MinMaxScaler().
from sklearn.preprocessing import MinMaxScaler
scaler = MinMaxScaler()
X[numerical_features] = scaler.fit_transform(X[numerical_features])
C. Gérer les jeux de données déséquilibrés
Il arrive régulièrement que les jeux de données soient déséquilibrés (dans notre cas 93% non churn vs 7% churn). Le risque est que le modèle prédit simplement tous ou la plupart des points comme la classe majoritaire car les données sont biaisées. En effet, certains modèles, comme les modèles linéaires, ne sont pas performants dans ce type de situation.
Pour la phase d'entraînement, il faut rééquilibrer les données, et pour la phase de test, il faut rester dans le contexte réel. A noter que certains modèles intègrent le rééquilibrage des données, cette étape n’est donc pas nécessaire.
Il y a deux approches pour rééquilibrer les données :

III. Méthode de scoring et interprétation
Entraînement des modèles
Afin de prédire les clients churn, nous avons entraîné plusieurs types d’algorithmes de classification : XGBoost, Random Forest, SVM et Logistic Regresion. Le modèle final est à sélectionner en fonction du cas d’usage et les contraintes liées au projet.
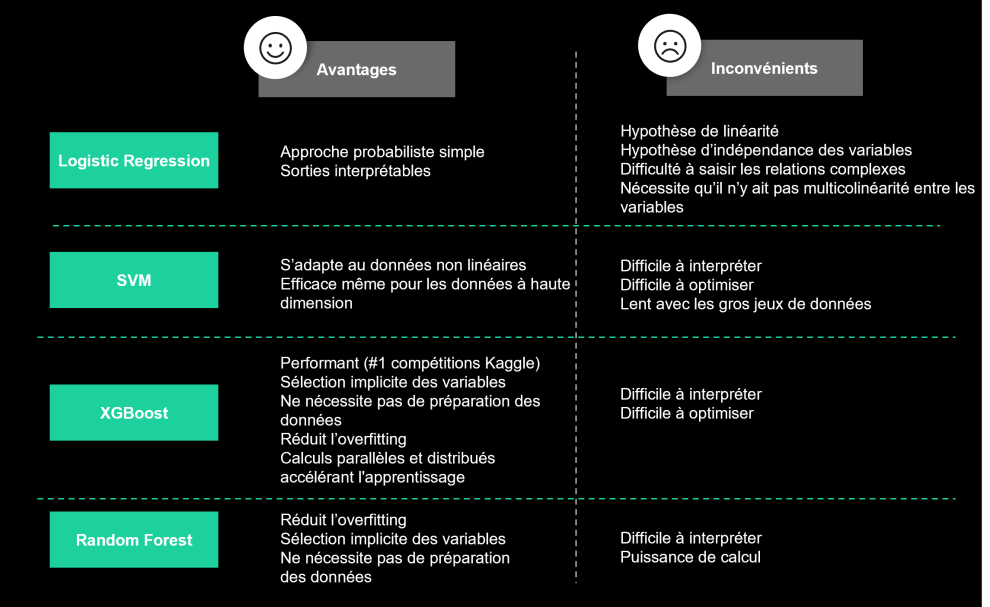
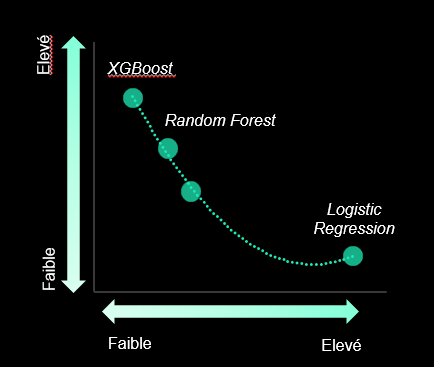
Il est possible d’optimiser les modèles en faisant varier leurs hyperparamètres. Dans notre cas d'usage, ces derniers ont été optimisés à partir d’une validation croisée k-fold.
Il existe deux méthodes pour réaliser cette optimisation d’hyperparamètres :

from sklearn.model_selection import RandomizedSearchCV, GridSearchCV
xgb = xgb.XGBClassifier()
# hyperparamètres
params = { "colsample_bytree": np.arange(0.5, 1.0, 0.1),
"gamma": uniform(0, 0.5),
"learning_rate": [0.01, 0.1, 0.2, 0.3], # default 0.1
"max_depth": randint(3, 7), # default 3
"n_estimators": randint(100, 200), # default 100
"subsample": np.arange(0.5, 1.0, 0.1),
"min_child_weight" : range(1,6,2)}
# Randomized Search
search = RandomizedSearchCV(xgb,
param_distributions=params,
random_state=42,
n_iter=20,
cv=5,
verbose=3,
n_jobs=1,
scoring='accuracy',
return_train_score=True)
# Grid Search
search = GridSearchCV(xgb,
param_distributions=params,
random_state=42,
n_iter=20,
cv=5,
verbose=3,
n_jobs=1,
scoring='accuracy',
return_train_score=True)
search_result = search.fit(X_train, y_train)
print("Best parameters:", search_result.best_params_)
print("Best score: ", search.best_score_)
xgb = search_result.best_estimator_
Pour approfondir sur l’optimisation d’hyperparamètres nous vous recommandons cet article medium.
La métrique à utiliser pour évaluer un modèle va également dépendre du cas d’usage. Dans notre cas, nous cherchons à maximiser le recall (rappel en français). En effet, pour notre cas d'usage Marketing, le but est de réduire au maximum les False Negative (FN). C'est-à-dire les clients qui sont des clients churn mais qui n'ont pas été prédits comme tels par le modèle.
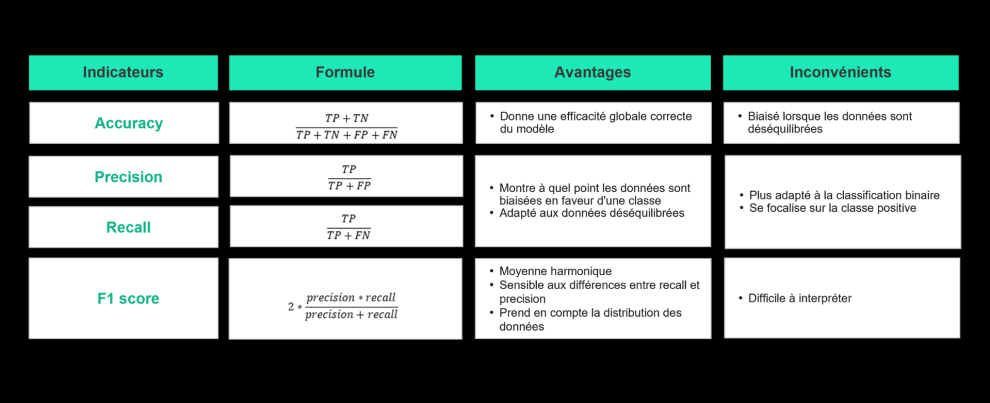
Pour approfondir sur les métriques nous vous recommandons cet article medium.
Performance du modèle
Les résultats dans cette section sont ceux du modèle XGBoost (meilleur modèle pour notre cas d’usage).
Le modèle produit pour chaque client un score correspondant à sa probabilité de churn. Ces clients sont qualifiés en churner/non churner en fonction d’un seuil qui sera à définir en fonction des besoins métier (note : le seuil est par défaut à 0.5)
Pour un seuil donné il est possible de produire une matrice de confusion afin de mesurer rapidement les résultats et les types d'erreurs du modèle.
Ici, la matrice de confusion permet de produire les mesures suivantes sur le modèle :
-
84% (sur 93%) des clients non churn
-
6.1% (sur 7%) des clients churn.
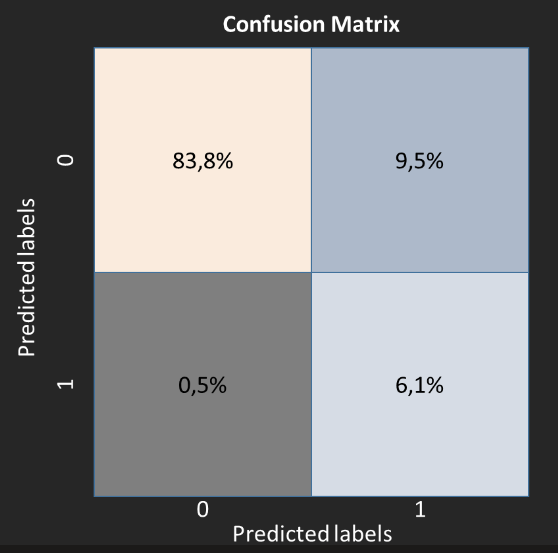
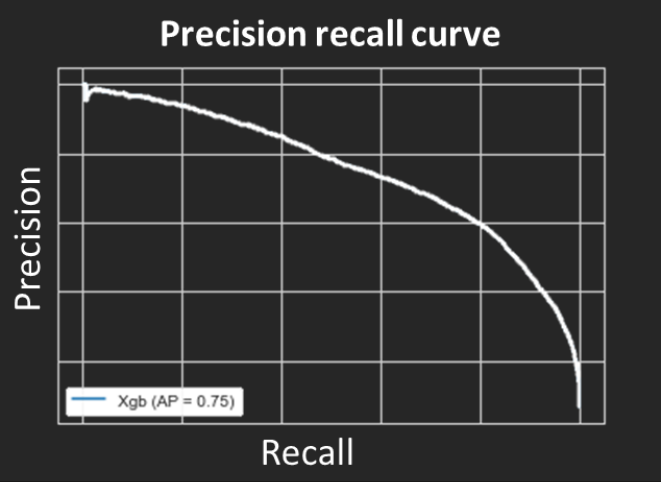
La métrique rappel est de 93% tandis que nous pouvons noter un bémol au niveau de la métrique précision qui est à 39%. En effet, le modèle prédit plus de clients churn qu'il y en a. Il y a un trade-off à faire entre ces deux métriques. Selon ce que l’on souhaite atteindre, le seuil de probabilité est à adapter afin d’obtenir un résultat jugé optimal. Lorsqu’on a un jeu de données déséquilibré, la courbe precision-recall curve permet de visualiser le résultat de ces deux métriques pour tous les seuils de probabilité.
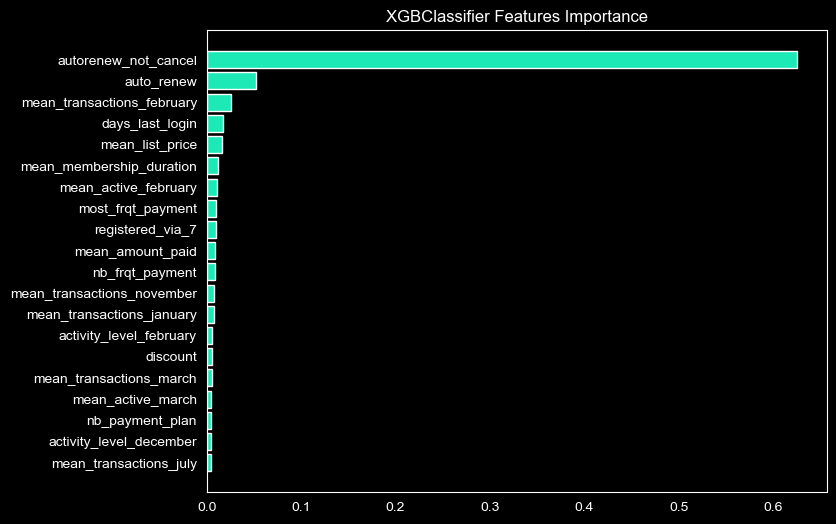
Dans tous les domaines, il y a un réel besoin de pouvoir expliquer, de manière globale ou locale, les variables responsables d’une prédiction. Le modèle XGBoost nous permet d’obtenir les variables les plus importante qui lui ont permis d’émettre une prédiction. Ces variables sont :
-
autorenew_not_cancel (le fait de renouveler tous ses abonnements automatiquement et en annuler aucun)
-
auto_renew (le fait de renouveler tous les abonnements automatiquement)
-
mean_transactions_february (montant de transactions moyen en février)
Ces variables clés sont à confronter avec le métier - par exemple chercher à comprendre pourquoi le mois de février a plus de poids dans la prédiction que les autres mois (i.e. il y a-t-il eu une action particulière côté KKBOX en février ?)
fig, ax = plt.subplots(figsize=(8,6))
ax.grid(False)
sorted_idx = xgb.feature_importances_.argsort()[-20:]
plt.barh(X_train.columns[sorted_idx], xgb.feature_importances_[sorted_idx], color = "#1DE9B6")
plt.title("XGBClassifier Features Importance")
Interprétation des résultats
Cette partie sera abordée dans un article suivant où nous interpréterons le modèle à partir de la librairie SHAP (librairie Python basée sur les valeurs de Shapley optimales en théorie des jeux).
Note : Les valeurs de Shapley calculent l’importance d’une variable en comparant ce qu’un modèle prédit avec et sans cette variable (en tenant compte de l’ordre). Cette approche permet d’expliquer les résultats de modèles de Machine Learning en estimant la contribution de chaque variable.
Conclusion
Cet article a permis de montrer pas à pas la construction d’un modèle de scoring pour prédire le potentiel d’attrition de clients (recall de 93%).
Pour aller plus loin, nous utiliserons la librairie SHAP afin de mieux connaître la relation positive et négative de la contribution des features à plusieurs échelles (globale/locale).
Le deuxième article se concentrera sur l’interprétation des résultats avec un état de l’art sur les différentes librairies possibles pour ce faire telles que SHAP, LIME, etc.


